Машина времени в Интернете
Опубликовано в журнале Инфоком
Вот, новый поворот
И мотор ревет
Что он нам несет
Радость или взлет?
Ну откуда же еще могут быть эпиграфы
в статье с таким-то названием?
Что такое
Интернет? Попробуйте сформулировать, предложите сделать это знакомым – все
ответы будут разными. Это не просто хранилище информации, а некая новая,
невиданная ранее сущность, имеющая экономические, этические, эстетические,
криминальные и прочие проявления в реальной, несетевой жизни. Многочисленные
публицисты-аналитики сравнивают Интернет то с гигантской свалкой, в которой есть
все, но неимоверно трудно найти то, что надо, то с бактерией, попавшей в
питательную среду и взрывообразно растущей за счет впитывания информации, то с
зыбучим песком, затягивающим психику каждого, кто соприкоснулся с этим чудом.
Нас же
сейчас интересует вопрос исторический, ведь Интернет представляется еще и этаким
бурлящим Солярисом, ежемесячно, ежедневно и ежечасно меняющим облик, внешний вид
и содержание бесчисленных страниц, да и сами страницы беспрестанно рождаются,
развиваются, некоторые умирают. Вся история Интернета, если считать от
изобретения Тимом Бернерсом Ли в 1994 году WWW, не
насчитывает и десяти лет, но учитывая необычайную насыщенность и динамичность
развития, видим, что по значимости событий и скорости их мелькания эти годы
соизмеримы с веками досетевого развития. Согласно статистике, средняя
"продолжительность жизни" веб-документа – около 100 дней, после этого он либо
изменяется, либо бывает просто удален. По тем же данным, средняя
продолжительность существования сайта равна 19 месяцам. Этот процесс неизбежно
связан с утерей старых страничек, исчезнувших сайтов, прежних вариантов
оформления ныне здравствующих проектов. А ведь это все представляет ценность –
ибо это наша с вами история, история человечества, история информации. Жалко.
На этот
пробел в нашей истории обратил внимание Брюстер Кахл, запустивший в 1995 году
проект Wayback Machine. Это сверхгигантский Интернет-архив, проводящий
постоянное сканирование сети и архивацию страничек. За неполные восемь лет в
единой базе данных собрано около 10 миллиардов страниц, включая графику. Темпы
прироста объема сохраняемой информации просто фантастические - ежедневно
добавляется около 250 гигабайт, более 12 терабайт данных поступает ежемесячно.
Сейчас (данные на осень 2002 года) база располагает документами, общий объём
которых составляет более 120 терабайт. Wayback Machine – сестринская компания
поисковика Alexa Internet,
поисковые пауки которого также участвуют в сборе данных в базу архива. Пауки или
спайдеры – программы, которые являются частью поисковых служб (типа Яндекса,
Google и .т.п.), и которые, двигаясь по ссылкам, закачивают веб-страницы для
дальнейшего их индексирования. Публичный доступ к Интернет архиву открыт с
октября 2001 года
Хочу! Хочу! Хочу!
Каждый, право, имеет право
На то, что слева и то, что
справа
Самое
приятное то, что доступ не только совершенно бесплатный (то есть даром), но и не
требует регистрации, заполнения форм, сообщения вашего почтового адреса,
обязательного ознакомления с правилами и подтверждения соглашения с ними –
непременных атрибутов всяких пустяшных копеечных проектов. (Вот бы на кого надо
равняться в этом вопросе.) И мы с вами запросто можем совершить путешествие по
времени. Для этого всего лишь надо набрать адрес http://www.archive.org/ и в единственное
окошечко ввести адрес странички, на которую вы хотите попасть в прошлом. (К
сожалению, пока Wayback Machine не располагает возможностью поиска по содержанию
сайтов, подобно поисковым серверам вроде Яндекса – так что для того, чтобы
попасть на необходимую страницу, пользователь должен знать её конкретный URL,
или, по крайней мере, адрес сайта.)
Вопрос в
выборе сайта? Если у вас есть страничка, которую вы несколько лет сопровождаете,
просиживая все ночи над оформлением и содержанием, обсуждением которой замучили
домочадцев и сослуживцев, не можете сосредоточиться на любом разговоре не по
теме вашей страничке, то для вас такого вопроса не существует. Конечно же,
отправляемся на Арбуз, размещавшийся раньше на Народе. Вводим адрес http://arbuz.narod.ru, жмем кнопку
"Take me back" (Переместите меня назад) и через минутку получаем меню с
запомненными в суперархиве вариантами.
Выбираем дату, конечно самую раннюю из предложенных, –
февраль 2001 года и через некоторое время с волнением встречаем восставший из
прошлого такой до боли знакомый выстраданный Арбуз двухлетней давности.
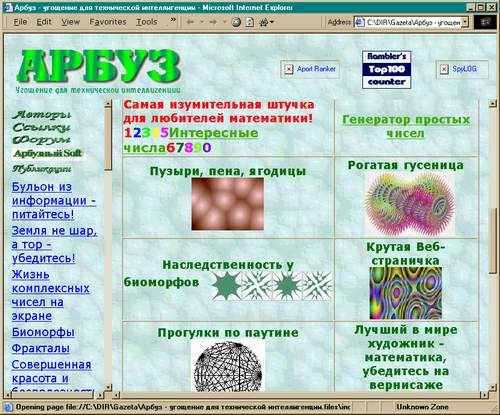
Конечно, все
было не так гладко, пришлось подождать с загрузкой и поковыряться в воссозданном
html – на Java-скрипты и кнопки
счетчиков машина времени выдавала предупреждения о невозможности их
восстановления. Но это такая мелочь перед радостью от встречи с любимым детищем,
тогда еще с фреймами, со счетчиком «Рамблер-100», без каскадных стилей, SSI и прочих поздних усовершенствований, атрибутов солидности
и зрелости.
Для
серьезной работы с архивами существует «страница специального поиска» http://web.archive.org/collections/web/advanced.html
, на которой можно уточнить временной диапазон и воспользоваться серией весьма
важных настроек. Так, например, здесь можно ограничить тип документов, по
которым производится поиск (один из вариантов – images, audio, video, binary,
text или PDF; по умолчанию стоит All types), определить, будет ли производится
поиск только однозначный поиск по заданной ссылке или следует учитывать подобные
варианты (выводить yahoo.com, www.yahoo.com и yahoo.com/index.html отдельно или
"расценивать" равными) и некоторые другие. При желании удалить ваши ресурсы из
архива можно воспользоваться специально предусмотренной для этого возможностью
великого архиватора.
Как это делается – трудовые будни волшебников
Кукол снимут с нитей длинных
И, засыпав нафталином,
В виде тряпок сложат в сундуках
Можно
предположить трудности, с которыми столкнулись разработчики Wayback Machine.
Даже простое обслуживание и сопровождение архива емкостью 120 терабайт
необычайно затруднительно. Поисковые машины, сканирующие сеть, должны сравнивать
найденные страницы (при канале 100 Мб/с это около 150 миллионов страниц за
неделю) с существующими в архиве для избежания копирования дублей, это
перегружает оперативную память и тормозит «паука».
Еще
трудности широкого поиска – нагрузка на сервера сайтов. Не каждый из них
способен выдержать натиск мощного поискового бота, "потребляющего" десятки
миллионов страниц ежедневно. Так что в данной ситуации возможны два выхода –
либо программа-робот будет достаточно "разумной" для того, чтобы ограничить
натиск на сервер, либо последний имеет все шансы "упасть". Да и сам сайт Wayback
Machine не всегда бывает доступен - иногда при заходе приходится любоваться
пояснением относительно того, что в связи с "непредвиденно высоким уровнем
запросов" сайт в дауне, или "Internet Archive Site временно недоступен в связи с
техобслуживанием". Следует отметить, что посещаемость у архива действительно
немаленькая, достигающая в среднем около 5 миллионов посетителей в сутки.
А кто же за
все это платит? Ведь ежегодно на покупку одних только винчестеров идёт около 40
000 долларов. Физически архив сосредоточен в трёх местах – два из них находятся
в районе Сан-Франциско, а ещё одна база расположена в новой библиотеке
Александрии, Египет. Той самой легендарной библиотеке Древнего мира, погибшей в
пожаре и восстановленной в наши дни, о ее необычной архитектуре писали в прессе
и неоднократно рассказывали по телевидению. Wayback Machine является
некоммерческим проектом и на сайте нет рекламы, которая могла бы хоть в
некоторой степени компенсировать расходы. В текущий момент финансирование
держится на добровольных взносах отдельных граждан и организаций, а также
грантах. Среди партнёров проекта, приведенных на главной странице, числятся
AT&T Research, Compaq (поглощенная Hewlett-Packard), Prelinger Archives, QuantumDLT, и Xerox PARC.
Кахл
возлагает надежды на создание объединенных проектов, и что Wayback Machine –
только первая из целой сети организаций, которые будут совместно выполнять
великую задачу – собирать и сохранять знания и делать их доступными для всего
человечества. Здорово, согласитесь, что в одно время с нами живут такие
замечательные люди.
Цифры взяты
из статьи http://www.computerra.ru/compulife/inet/22743/
, которая, в свою очередь, ссылается на такие источники: http://www.archive.org/
http://www.newscientist.com/opinion/opinterview.jsp?id=ns23701
http://www.mindjack.com/feature/archive.html
http://www.infotoday.com/online/mar02/OnTheNet.htm
А знаете,
что самое интересное в этом нашем путешествии по времени? Ссылки, расположенные
на найденных в прошлом страничках, ведут не на современные сайты, а на другие
сохранённые страницы. Таким образом, вы в самом прямом смысле находитесь и
путешествуете в "Интернете прошлого". Представляете?
|